¿Alguna vez has visto un video de TikTok con subtítulos en tiempo real? ¿O le has preguntado a tu altavoz inteligente por el clima? Si asintió con la cabeza, ya ha utilizado el Reconocimiento Automático del Habla (RAH). Esta tecnología de IA procesa el habla humana en texto legible y que se puede buscar, y es el motor invisible detrás de las aplicaciones que usamos todos los días.
Un Escriba Digital para la Era Moderna
Piensa en el RAH como un transcriptor digital increíblemente rápido. Es la IA que impulsa las herramientas de las que dependemos a diario, desde la función de voz a texto de tu teléfono hasta los subtítulos en vivo en tu última videollamada. Para comprender completamente qué es el RAH, debes verlo como un componente central de el campo más amplio de la Inteligencia Artificial (IA). Los sistemas de RAH utilizan algoritmos sofisticados para analizar las formas de onda de audio, identificar patrones en el habla humana y convertir esos patrones en texto.
Esta capacidad hace que los datos de audio y video sean más accesibles y valiosos que nunca. Por ejemplo, sin el RAH, tus comandos de voz a dispositivos como Siri o Alexa simplemente no funcionarían. Es el primer paso fundamental que convierte las palabras habladas en datos que las computadoras pueden realmente entender y actuar sobre ellos.
La Creciente Importancia del RAH
Y la demanda de esta tecnología está explotando. Como pieza clave de la IA conversacional, el mercado global de software de RAH está en una trayectoria de crecimiento masivo, proyectado para saltar de USD 5.49 mil millones a unos increíbles USD 59.39 mil millones para 2035. Esa es una tasa de crecimiento anual compuesta (CAGR) del 26.67%, lo que demuestra lo profundamente integrado que se está volviendo en nuestras vidas. Puedes profundizar en el análisis completo del mercado para comprender más sobre este crecimiento explosivo.
El RAH ya no es un concepto futurista; es una utilidad fundamental que desbloquea el valor oculto dentro del contenido hablado, haciéndolo buscable, analizable y accesible para todos.
Algunos factores clave están impulsando esta rápida adopción:
- Accesibilidad Mejorada: Ofrece subtítulos para personas con problemas de audición y hace que el contenido de audio sea buscable para todos.
- Información de Datos: Las empresas pueden transcribir llamadas o reuniones de clientes para analizar los comentarios y detectar tendencias.
- Eficiencia Mejorada: Los profesionales pueden convertir rápidamente entrevistas, conferencias y notas en texto, ahorrando horas de minucioso trabajo manual.
A medida que esta tecnología sigue mejorando, su presencia en nuestras vidas digitales solo se volverá más fluida y esencial.
Cómo la Tecnología RAH Traduce el Habla en Texto
En esencia, el Reconocimiento Automático del Habla (RAH) es un poco como enseñarle a una computadora a hacer lo que un transcriptor humano hace de forma natural: escuchar a alguien hablar y escribirlo todo. La tecnología toma un archivo de audio sin procesar, que en realidad es solo una onda de sonido continua, y metódicamente lo convierte en texto limpio y legible. Es un proceso fascinante que combina acústica, lingüística y una IA muy poderosa.
Esta imagen desglosa ese recorrido de alto nivel del sonido al texto.
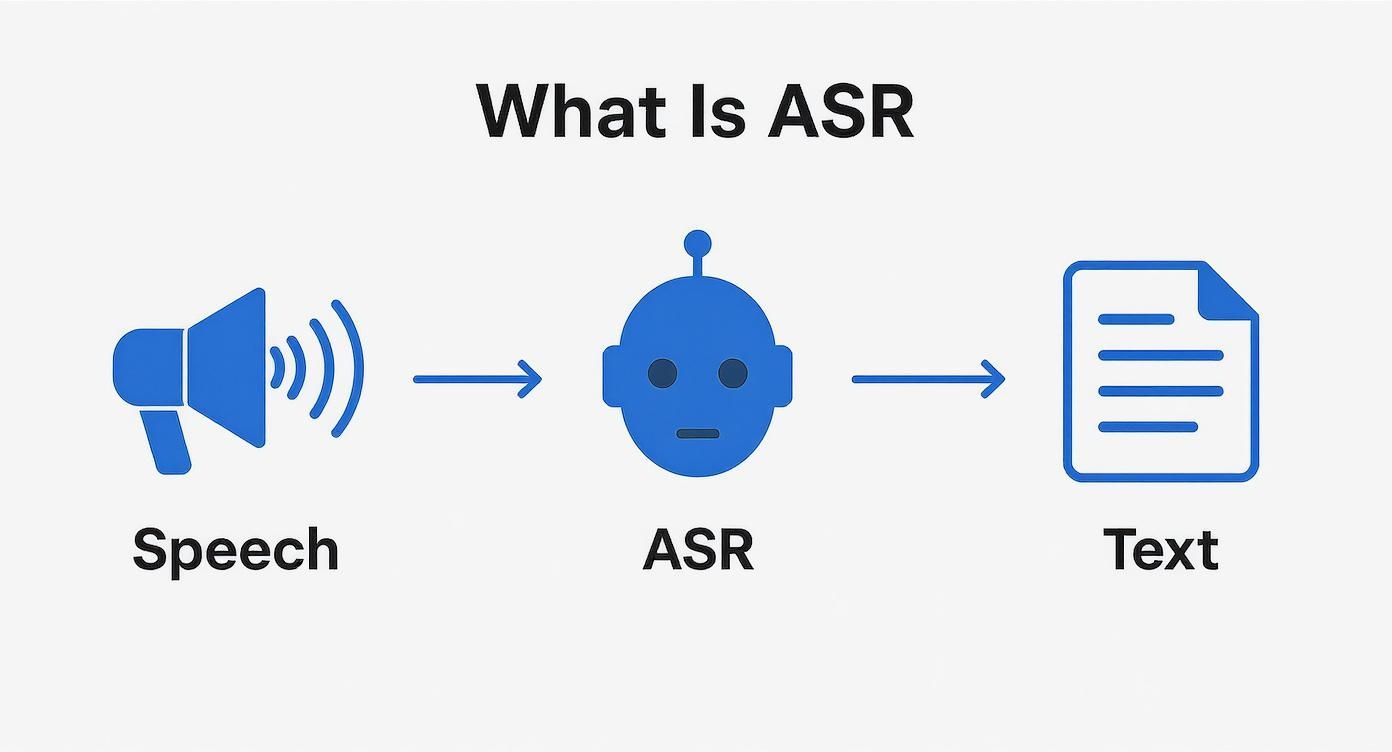
Como muestra la infografía, el sistema RAH es el puente esencial entre una onda de sonido hablada y un documento de texto final. Lograr esta conversión fundamental correctamente es el primer y más crítico paso para desbloquear el valor oculto en cualquier dato de audio.
Hoy en día, existen dos enfoques principales para el Reconocimiento Automático del Habla. Comprender ambos ayuda a explicar por qué el RAH ha mejorado tanto en los últimos años.
El Enfoque Híbrido Tradicional
El primer método es el modelo híbrido tradicional. Piensa en ello como una línea de montaje altamente especializada con un equipo de expertos. Cada experto tiene un trabajo específico, y la transcripción final es tan buena como el eslabón más débil de la cadena.
Este enfoque combina tres modelos separados:
- El Modelo Acústico: Este especialista es el oyente. Su trabajo es tomar las formas de onda de audio y predecir las unidades de sonido más pequeñas, llamadas fonemas. Básicamente, responde a la pregunta: "¿Qué sonidos individuales estoy escuchando ahora mismo?"
- El Modelo Léxico: Este es el diccionario del equipo. Toma la secuencia de fonemas del Modelo Acústico y los mapea a palabras reales. Es la parte que sabe que los sonidos "h-eh-l-o" coinciden con la palabra "hola".
- El modelo lingüístico: Este es el gurú de la gramática. Analiza una secuencia de palabras y predice lo que es más probable que venga a continuación basándose en patrones estadísticos. Así es como el sistema distingue entre frases sensatas como "escribir una carta" y frases sin sentido como "derecho a una carta."
Estos tres componentes tenían que funcionar en perfecta secuencia para construir el texto final. Si bien este método funcionó durante años, tenía un cuello de botella importante: cada parte tenía que entrenarse por separado, lo que requería mucho tiempo y trabajo, y la precisión finalmente se estancó.
El enfoque moderno de IA de extremo a extremo
El segundo método, y mucho más reciente, es el modelo de IA de extremo a extremo. En lugar de esa cadena de montaje, imagine a un solo experto brillante que aprendió su oficio escuchando millones de horas de audio del mundo real. Este experto descubre cómo mapear el sonido directamente al texto en un solo paso fluido.
Este es el motor que impulsa los sistemas ASR más avanzados de la actualidad.
Un modelo de IA de extremo a extremo no necesita modelos acústicos, léxicos y lingüísticos separados. Emplea un único modelo unificado que mapea directamente una secuencia de características acústicas de entrada en una secuencia de palabras. Aprende todas las relaciones complejas y desordenadas entre los sonidos, las palabras y la gramática simultáneamente analizando conjuntos de datos masivos.
Este enfoque unificado no solo es más eficiente, sino que también es mucho más preciso. Al aprender de una dieta tan vasta y variada de audio, estos modelos de IA mejoran mucho en el manejo del caos del mundo real, como los acentos, el ruido de fondo y la jerga.
Este método moderno es la verdadera razón por la que estamos viendo avances tan dramáticos en la calidad de la transcripción. Si desea ver esta tecnología en acción, nuestra guía sobre la conversión de audio a texto ofrece una mirada práctica a cómo funcionan estos sistemas. La asombrosa capacidad de estos modelos de extremo a extremo para aprender y adaptarse constantemente es lo que está acercando a ASR a la precisión a nivel humano.
Explorando los sistemas ASR tradicionales frente a los modernos
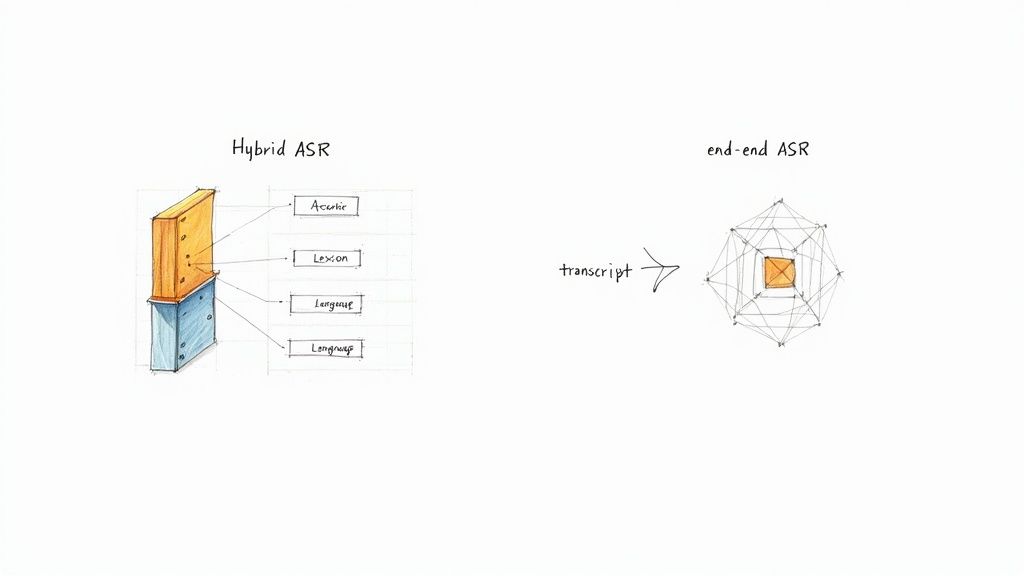
Si echa un vistazo al interior del Reconocimiento Automático del Habla, encontrará dos motores completamente diferentes en funcionamiento. Durante años, el campo estuvo dominado por un enfoque tradicional de varias partes. Pero más recientemente, un método unificado impulsado por la IA se ha hecho cargo, ofreciendo avances en precisión y accesibilidad.
Comprender este cambio es la clave para ver por qué ASR ha mejorado tan dramáticamente en tan poco tiempo.
Los sistemas "híbridos" de la vieja escuela eran inteligentes, pero también eran increíblemente complicados. Chocaron contra un muro de precisión porque estaban hechos de tantas piezas separadas y ajustadas a mano. Cada parte requería su propio equipo de especialistas y una gran cantidad de trabajo manual, como fonetistas expertos, para hacerlo bien.
Piénselo: solía necesitar fonetistas expertos solo para construir el diccionario fonético de su sistema. Esto hizo que los modelos tradicionales no solo fueran complejos y costosos de crear, sino también agonizantemente lentos de mejorar.
Los modelos de IA modernos de extremo a extremo cambiaron el guion por completo. Estos sistemas aprenden directamente de cantidades masivas de audio, evitando por completo la necesidad de componentes separados y construidos a mano.
La ventaja de la IA en el reconocimiento de voz
Entonces, ¿por qué el gran cambio a la IA? Realmente se reduce a algunas ventajas principales, comenzando con la precisión.
Los modelos de extremo a extremo se entrenan con millones de horas de audio del mundo real. Esto significa que son mucho mejores para manejar el hermoso desorden del habla humana, desde acentos marcados y dialectos regionales hasta ruido de fondo y personas que hablan entre sí.
Este enfoque también simplifica radicalmente todo el proceso de entrenamiento. En lugar de hacer malabarismos con tres modelos separados, los desarrolladores pueden concentrarse en un solo sistema unificado. Esto facilita mucho la actualización y la mejora del rendimiento. A medida que la IA conversacional se vuelve más inteligente, también lo hacen las herramientas basadas en ella. Puede ver esta evolución en acción cuando observa si ChatGPT puede transcribir audio y su lugar en este nuevo panorama.
Una comparación directa
Para que las diferencias queden claras, es útil ver estos dos enfoques uno al lado del otro. El contraste en su arquitectura, las necesidades de datos y el potencial de mejora muestra exactamente por qué la industria se ha movido de manera tan decisiva hacia la IA.
Diferencias clave entre los enfoques de ASR
| Aspecto | Enfoque híbrido tradicional | ---Enfoque de IA de extremo a extremo |
|---|---|---|
| Componentes | Modelos de léxico + acústico + lenguaje | Modelo único unificado |
| Datos de entrenamiento | Requiere datos alineados por la fuerza | Funciona con pares audio-texto no alineados |
| Trabajo humano | Alto (fonetistas, alineación manual) | Mínimo |
| Tendencia de precisión | Estancado | Mejorando continuamente |
| Complejidad de la configuración | Alta (múltiples modelos independientes) | Menor (sistema integrado único) |
| Personalización | Requiere conocimientos y esfuerzo de expertos | Se puede ajustar con nuevos datos |
Como puede ver, las ventajas prácticas de los modelos de IA modernos son enormes. Su arquitectura más simple y el proceso de aprendizaje basado en datos no solo producen mejores resultados, sino que también abren la puerta a una innovación mucho más rápida en el reconocimiento de voz.
Medición de la precisión de ASR con la tasa de error de palabras
Entonces, ¿cómo sabemos si un sistema de reconocimiento de voz es realmente mejor que otro? El estándar de la industria para medir la precisión de ASR es una métrica llamada Tasa de error de palabras (WER).
Piense en ello como una forma simple y directa de calificar una transcripción generada por máquina en comparación con una transcripción de referencia perfecta y verificada por humanos.
WER calcula el porcentaje de errores contando cada error que comete el ASR. La fórmula es: WER = (Sustituciones + Eliminaciones + Inserciones) / Número de palabras en la transcripción de referencia. Esa suma se divide luego por el número de palabras en la transcripción correcta.
¿El objetivo? Obtener el WER más bajo posible. Una puntuación más baja significa una transcripción más precisa.
Un WER de 10% significa que la transcripción es 90% precisa. Un sistema de primer nivel podría alcanzar un WER de 3%, obteniendo 97% de las palabras correctas. Esa pequeña diferencia de porcentaje puede ser el factor decisivo entre una herramienta útil y un desastre frustrante.
Por qué WER no es toda la historia
Si bien WER es el estándar de la industria para medir la precisión de ASR, no captura la imagen completa de cómo se desempeña un sistema en el mundo real. Una puntuación baja es excelente, pero la vida rara vez sucede en un estudio silencioso e insonorizado.
El audio del mundo real presenta múltiples desafíos que pueden confundir incluso a los modelos más avanzados.
Estos son algunos de los desafíos más comunes:
- Ruido de fondo: El ruido de una cafetería, el tráfico de la calle o la mala calidad del audio pueden confundir fácilmente al sistema.
- Interlocutores superpuestos: Cuando las personas se hablan entre sí, el ASR tiene dificultades para separar el diálogo y asignarlo a la persona correcta.
- Acentos y dialectos: Los modelos entrenados con inglés americano o británico "estándar" pueden ser interrumpidos por acentos o estilos de habla únicos.
- Jerga específica de la industria: Los términos técnicos, los nombres de marcas o la jerga que no están en el vocabulario del modelo a menudo se transcriben en algo completamente extraño.
Estos problemas del mundo real son exactamente la razón por la que un buen convertidor de audio a texto necesita ser robusto. Un sistema puede tener un WER impresionante en datos de laboratorio limpios, pero su verdadero valor se demuestra por lo bien que maneja la naturaleza desordenada e impredecible del audio cotidiano. Aquí es donde los modelos de IA modernos, entrenados en millones de horas de sonido diverso, realmente comienzan a distanciarse de las tecnologías más antiguas.
Aplicaciones del mundo real de la tecnología ASR
El reconocimiento automático de voz se ha salido del laboratorio y se ha extendido mucho más allá de los comandos de voz simples. Hoy en día, el ASR moderno ofrece un valor medible en diversas industrias como telefonía, plataformas de video y monitoreo de medios.
Puedes ver este cambio en todas partes. El Reconocimiento Automático del Habla (RAH) es ahora el motor principal que impulsa todo el campo del reconocimiento de voz, con un crecimiento explosivo en el servicio al cliente, la atención médica y los medios de comunicación. Características que antes parecían ciencia ficción, como la transcripción en tiempo real, ahora son solo parte del flujo de trabajo.
Transformando la interacción con el cliente y los medios de comunicación
En ningún lugar el impacto del RAH es más claro que en el centro de contacto moderno. En el pasado, los gerentes revisaban manualmente una pequeña muestra aleatoria de las llamadas de los clientes para el control de calidad. Era un tiro a ciegas. Ahora, pueden transcribir el 100% de sus interacciones.
Este simple cambio convierte un flujo de audio no estructurado en una base de datos searchable y analizable. Las empresas pueden escanear instantáneamente las llamadas para detectar el sentimiento del cliente, identificar problemas recurrentes y confirmar que los agentes se adhieren a los scripts de cumplimiento. Es un cambio completo de ser reactivo a ser proactivo y basado en datos.
El mundo de los medios y el entretenimiento también se ha transformado.
- Plataformas de video: Piensa en servicios como YouTube. Utilizan el RAH para generar automáticamente subtítulos, haciendo que su contenido sea accesible al instante para una audiencia global y para personas sordas o con problemas de audición.
- Monitoreo de medios: Las marcas ahora utilizan el RAH para escanear miles de horas de podcasts y noticias transmitidas. Pueden rastrear las menciones de su empresa, medir la opinión pública y medir el impacto real de sus campañas de relaciones públicas.
- Creación de contenido: Los editores de video y los podcasters usan transcripciones de RAH para reducir el tiempo de producción. En lugar de revisar horas de audio para encontrar una cita específica, pueden simplemente presionar
Ctrl+F.
Impulsando la productividad en el lugar de trabajo moderno
Las reuniones virtuales son la columna vertebral del trabajo moderno, y el RAH las está haciendo mucho más efectivas. Plataformas como Zoom y Google Meet utilizan la tecnología para proporcionar transcripción en tiempo real, por lo que nadie se pierde un punto crucial.
Pero la verdadera magia ocurre después de que termina la reunión. Estas transcripciones se convierten en activos invaluables. Puedes usarlas para generar actas de reunión instantáneas, extraer elementos de acción y crear un registro permanente y searchable de cada decisión. Elimina por completo la necesidad de tomar notas frenéticamente. Al observar lo que impulsa estas características, a menudo encontrarás revisiones del software de conversión de voz a texto más importante que las impulsa.
El verdadero valor del RAH reside en su capacidad de convertir conversaciones habladas no estructuradas y fugaces en datos estructurados y permanentes que pueden ser analizados, buscados y reutilizados.
Desde la transcripción de conversaciones médico-paciente en el cuidado de la salud hasta ayudar a los estudiantes a convertir las conferencias en guías de estudio, las aplicaciones siguen creciendo. El RAH es la clave que desbloquea el valor masivo oculto dentro de la palabra hablada.
Preguntas frecuentes sobre el RAH
A medida que te familiarizas con el Reconocimiento Automático del Habla, tienden a surgir algunas preguntas comunes. Resolverlas ayuda a aclarar cómo el RAH encaja en el mundo más amplio de la tecnología de voz y la inteligencia artificial. Aclaremos cualquier confusión persistente.
¿Cuál es la diferencia entre RAH y PNL?
Piensa en el RAH como los oídos y el Procesamiento del Lenguaje Natural (PLN) como el cerebro; trabajan juntos en las aplicaciones de IA de voz.
- RAH (Reconocimiento Automático del Habla) son los oídos de la operación. Su única función es convertir el audio hablado en texto escrito. Responde a la pregunta: ¿qué se dijo?
- PNL (Procesamiento del Lenguaje Natural) es el cerebro. Toma el texto que proporciona el RAH y lo analiza para comprender el significado, la intención y el sentimiento.
Imagina esto: le preguntas a tu altavoz inteligente: "¿Cómo estará el clima en Londres mañana?" El RAH hace la primera parte, convirtiendo tu voz en el texto: "¿Cómo estará el clima en Londres mañana?". Luego, la PNL entra en acción, analizando ese texto para averiguar tu solicitud principal, un pronóstico del tiempo para un lugar y un tiempo específicos, para que el dispositivo pueda obtener la información correcta para ti.
¿El RAH es lo mismo que la conversión de voz a texto?
Sí. Para todos los efectos prácticos, el RAH y la conversión de voz a texto se utilizan indistintamente. Ambos se refieren a la misma tecnología.
"Reconocimiento Automático del Habla" es la tecnología subyacente, mientras que "conversión de voz a texto" describe la función que realiza. Si estás buscando una herramienta que convierta el audio en palabras, buscar cualquiera de los términos te llevará a donde necesitas ir.
¿Cuál es la diferencia entre reconocimiento de voz y reconocimiento de voz?
Este es un punto de confusión clásico, pero la distinción es en realidad bastante simple. El reconocimiento de voz transcribe lo que se dice, mientras que el reconocimiento de voz identifica quién está hablando.
Reconocimiento de voz se trata de identificar qué se está diciendo. El objetivo es transcribir palabras habladas en texto, sin importar quién esté hablando. Una herramienta que genera subtítulos para un video de YouTube o crea actas de reuniones está utilizando el reconocimiento de voz.
Reconocimiento de voz, a menudo llamado reconocimiento del hablante o biometría de voz, se centra en identificar quién está hablando. Analiza las huellas de voz únicas para hacer coincidir una voz. Un sistema de seguridad que desbloquea tu teléfono cuando dices una frase específica está utilizando el reconocimiento de voz para confirmar que realmente eres tú.
En resumen: El reconocimiento de voz crea transcripciones. El reconocimiento de voz etiqueta a los hablantes.
¿Qué tan preciso es el ASR moderno en comparación con los humanos?
Aquí es donde las cosas se ponen realmente interesantes. En condiciones ideales, piensa en una persona hablando claramente a un buen micrófono en una habitación tranquila, los mejores sistemas ASR modernos pueden lograr tasas de error de palabras por debajo del 5%, acercándose a la precisión a nivel humano.
Pero el mundo real es desordenado. El rendimiento varía con el ruido de fondo, los acentos y los hablantes superpuestos, donde los humanos aún mantienen ventajas en la comprensión contextual. Dicho esto, la brecha de precisión se está cerrando a un ritmo increíble a medida que los sofisticados modelos de IA aprenden de vastas cantidades de datos de audio todos los días.
¿Listo para poner a trabajar esta poderosa tecnología? MeowTxt ofrece una solución simple de pago por uso para convertir tus archivos de audio y video en texto preciso y editable en minutos. Pruébalo gratis y obtén tus primeros 15 minutos de transcripción por nuestra cuenta.


