
Ever wonder how your podcast, meeting recording, or voice memo magically turns into a wall of text? The magic is a technology called Automated Speech Recognition, or ASR. This powerful audio to text process has become an essential tool for creators, businesses, and researchers.
You can think of ASR as a digital brain that has learned to listen and write—just like a person, but at warp speed. It's the core engine that powers every modern audio to text service.
How Does Audio to Text Actually Work?
The whole process feels instant, but under the hood, a logical sequence of analysis is happening. It all starts with the sound itself. An audio to text converter doesn't hear words; it processes data.
From Sound Waves to Syllables
When you talk, you’re really just creating vibrations in the air—sound waves. An ASR system's first job is to capture those waves and turn them into a digital signal. This part is called acoustic modeling.
The system then slices that complex audio signal into the tiniest, most basic units of sound, called phonemes. These are the building blocks of speech, like the "k" sound in "cat" or the "sh" sound in "shoe."
It’s a lot like how we first learn to read by sounding out individual letters. The AI sifts through these phonemes, cross-references them against a massive library of known sounds, and figures out the most likely matches. This initial step is critical for accurate audio to text conversion.
At its core, audio-to-text technology isn't just listening; it's predicting. It constantly calculates the probability of which word is most likely to follow another, creating coherent sentences from a stream of individual sounds.
Assembling Words into Sentences
Once the system has a string of potential sounds, it kicks off the next phase: language modeling. This is where context is king in the audio to text process.
The ASR uses sophisticated algorithms to look at the sequence of phonemes and decide on the most logical combination of words. It knows, for example, that the phrase "ice cream" is far more likely to pop up in conversation than "eyes cream."
This infographic gives you a simple visual of the whole journey, from sound input to text output.
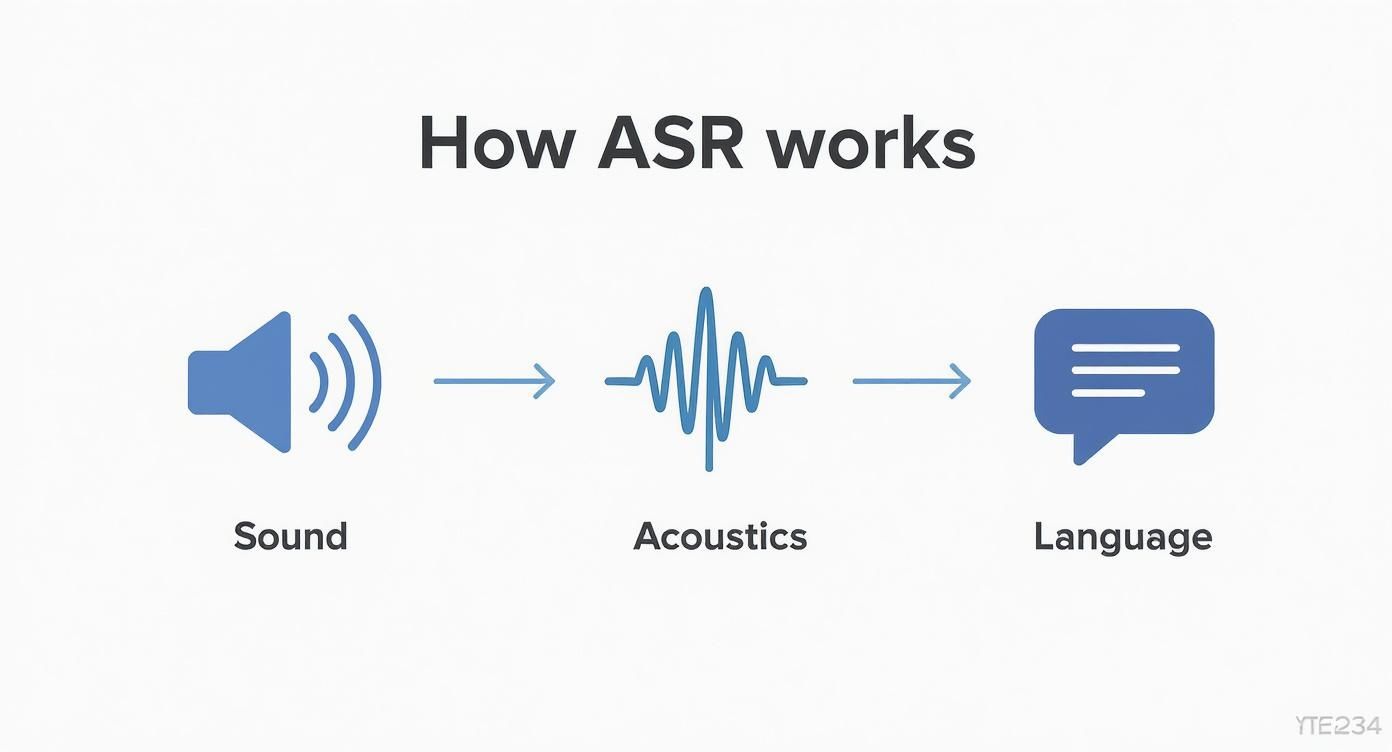
As you can see, the raw sound is analyzed for its acoustic properties first. Then, it’s interpreted using language and context to produce the final text. This two-step process is what lets an AI tackle the beautiful messiness of human speech and deliver a high-quality audio to text transcript.
To really get a handle on the mechanics, it helps to look into modern AI integration in post-production, which is pushing the boundaries of what this tech can do. By understanding both the acoustic and language models, you start to see how today's transcription tools can deliver such mind-bogglingly good results.
The Journey of Speech Recognition Technology
The magic of turning spoken words into text on a screen feels incredibly modern, but its roots dig much deeper than you might think. This journey started in labs filled with clunky, room-sized computers—a world away from the sleek audio to text apps in our pockets today. Understanding how we got here is the key to appreciating just how powerful and accessible transcription has become.
The first real attempt at speech recognition dates all the way back to the 1950s with Bell Laboratories' "Audrey" system. Rolled out in 1952, this beast of a machine could recognize spoken digits from zero to nine. But there was a catch: you had to pause between each number, and its accuracy plummeted if it didn't recognize your voice. Cool, but hardly practical. You can dive deeper into the history of speech-to-text here.
The Shift to Probabilistic Models
For a long time, progress crawled along. Early systems were rigid, trying to match audio waveforms to a pre-defined template. This rule-based approach was brittle and fell apart when faced with the natural chaos of human speech—different accents, pitches, and tones threw it completely off course.
The real breakthrough came when researchers started using statistical methods, especially Hidden Markov Models (HMMs), which took off in the 1980s. Instead of looking for an exact match, HMMs played the odds.
Think of it like a weather forecast for words. An HMM doesn't just identify a single sound; it calculates the probability of a sequence of sounds forming a specific word, and then the probability of that word showing up in a sentence.
This probabilistic thinking was a complete game-changer. It let systems make educated guesses based on context, which massively improved their accuracy and flexibility. Suddenly, real-world commercial uses for audio to text technology seemed possible.
Deep Learning and the Modern Era
The next great leap forward came with the rise of deep learning and neural networks in the 2010s. These AI systems, which are loosely inspired by the structure of the human brain, could chew through gigantic amounts of data and learn the subtle patterns of language all on their own.
Today's audio to text tools are powered by these incredibly advanced networks. They've been trained on millions of hours of diverse audio, which lets them handle:
- Multiple Accents: Recognizing speech from a global range of speakers.
- Background Noise: Isolating voices from the chatter in a busy café.
- Rapid Speech: Keeping up with fast-paced conversations and interviews.
This constant training is why modern audio to text services can hit accuracy rates of 95% or higher in ideal conditions. The leap from Audrey recognizing single digits to an AI transcribing a complex, natural conversation is nothing short of incredible.
Automated vs. Human Transcription: Which One Is Right For You?
When it comes to turning audio into text, you’re standing at a fork in the road. Do you go with a speedy AI service or a detail-oriented human professional? There's no single right answer—the best choice really boils down to your project's specific needs, balancing four key factors: accuracy, speed, cost, and security.
Think of an AI-powered service as the sprinter. For clean, high-quality audio—like a solo podcast or a quiet one-on-one interview—it's unbelievably fast and can deliver surprisingly accurate audio to text results in just a few minutes. This lightning-fast turnaround is a game-changer for content creators and marketers who need to get transcripts, captions, or show notes out the door ASAP.
But where AI often trips up, a human transcriber really shines.
The Trade-Off Between Speed and Nuance
Let's be clear: human transcription is slower and costs more. A professional might take a few hours or even a full day to transcribe a one-hour file that an AI could finish in under five minutes. But what you're paying for is a human's incredible ability to understand nuance, context, and complexity.
A person can easily untangle overlapping conversations, recognize niche industry jargon, and make sense of speakers with thick accents or quirky speech patterns. This human touch becomes essential for projects where every single word matters, like legal depositions, medical records, or detailed academic research. While many common tasks, like transcribing interviews, are now handled by sophisticated AI video editing tools for transcription, the need for human precision in high-stakes scenarios remains.
The core difference is simple: AI transcribes what it hears based on patterns, while a human transcribes what was meant based on understanding. This is crucial when dealing with sarcasm, humor, or ambiguous language that audio to text algorithms can easily misinterpret.
A Head-to-Head Comparison
To make the decision a little easier, let's put the two options side-by-side. Seeing their strengths and weaknesses laid out can help you pick the perfect approach for your next audio to text project.
Here’s a direct look at how automated and human transcription services stack up across the factors that matter most.
Automated vs Human Transcription Head-to-Head
| Feature | Automated Transcription (AI) | Human Transcription |
|---|---|---|
| Accuracy | Up to 95%+ on clear audio; struggles with noise and accents. | Consistently 99%+; excels with complex audio. |
| Turnaround | Minutes for a one-hour file; almost instantaneous. | Several hours to days, depending on audio length. |
| Cost | Very low, often just a few cents per minute. | Significantly higher, typically $1.00 or more per minute. |
| Security | Varies by provider; look for encryption and data privacy policies. | Relies on individual or company confidentiality agreements. |
Ultimately, the choice hinges on your priorities. If you need it done fast and cheap for a good-quality recording, an audio to text AI is your best bet. But if pinpoint accuracy is non-negotiable, nothing beats the nuanced understanding of a human expert.
Factors That Influence Transcription Accuracy
Not all audio is created equal. Far from it. The quality of your source file is the single biggest factor that will make or break your audio to text transcription.
Think of an ASR model like a diligent student trying to take notes in a noisy lecture hall. The clearer the speaker, the better the notes. If your recording is pristine, you can expect accuracy rates sailing past 95%. But start throwing in common problems, and that number can plummet pretty fast.
The goal is simple: give the audio to text engine the cleanest possible signal to work with. Understanding what messes things up helps you get your recordings right from the start, saving you hours of painful clean-up later.
Audio Quality and Clarity
The bedrock of any great transcript is high-quality audio. This isn't about having a professional studio, but it does mean using a decent microphone and placing it close to the speaker. Audio captured from a laptop’s built-in mic across the room will always sound thin and distant, making it a nightmare for audio to text systems to decipher.
On a more technical level, things like the recording format and bitrate also play a part. A heavily compressed, low-quality MP3 file literally throws away audio data to save space. That lost information can make it much harder for an AI to tell the difference between similar-sounding words.
For a deeper dive into getting the best possible sound, check out our guide on how to improve audio quality for transcription.
The rule of thumb is simple: if it’s difficult for a human to understand, it will be ten times harder for an AI. Clear, crisp audio is the best investment you can make for an accurate audio to text transcription.
Background Noise and Speaker Variables
Even with a great microphone, the recording environment can sabotage your efforts. An ASR system can’t easily separate a speaker's voice from background chatter, a humming air conditioner, or passing traffic. Every extra sound adds another layer of confusion that muddles the signal for the audio to text converter.
Beyond just noise, how people speak is a massive influence. The main culprits here are:
- Multiple Speakers: When people talk over each other, the dialogue becomes a tangled mess that AI struggles to unpick.
- Strong Accents: Modern systems are trained on a huge diversity of accents, but very thick or uncommon dialects can still throw them for a loop.
- Pacing and Diction: Speaking incredibly fast or mumbling your words makes it tough for the AI to pinpoint where one word ends and the next begins.
By controlling these factors—recording in a quiet space, encouraging speakers to talk one at a time, and speaking clearly—you’re setting your audio to text tool up for a win.
How to Choose the Right Audio to Text Service

The market is flooded with audio to text tools, and picking the right one can feel a bit like spinning a roulette wheel. The truth is, the "best" service is simply the one that slots perfectly into your world. To find it, you just need to weigh your options against a few key factors. This quick framework will help you find an audio to text platform that matches your workflow, budget, and project goals.
First up, check the language and dialect support. Does the service actually handle the languages you work with? Some platforms are a jack-of-all-trades, while others specialize. If your recordings are full of regional accents or specific dialects, you'll want to find an audio to text service known for its accuracy with diverse speakers.
Next, think about how it will mesh with your current setup. Look at the integration options available. Can you zap a transcript straight into Google Docs, or download an SRT file for your video editor with one click? A smooth workflow isn't just a nice-to-have; it's a massive time-saver.
Security and Pricing Models
When you're dealing with sensitive conversations, security is non-negotiable. Hunt for audio to text services that offer end-to-end encryption and have a crystal-clear data privacy policy. A platform worth its salt will be upfront about how it protects your files, ensuring that confidential client meetings or private interviews stay that way.
Choosing a service isn't just about features; it's about trust. Your audio files contain important information, and the right audio to text platform will prioritize its protection with robust security measures from upload to deletion.
Pricing models are all over the map. Some services will try to lock you into a monthly or annual subscription, which can sting if your transcription needs are sporadic. Others offer a more flexible pay-as-you-go model, letting you pay only for the minutes you actually convert. This is perfect for one-off projects or if you’re just dipping your toes into using an audio to text converter.
The technology has come an incredibly long way. The 2000s and 2010s saw explosive growth, thanks to cloud computing and AI. Google’s Voice Search, for instance, collected enormous amounts of speech data, eventually building a database of 230 billion words and hitting nearly 80% accuracy by 2001. That early work set the stage for the powerful audio to text tools we have today.
By carefully weighing language support, integrations, security, and pricing, you can confidently pick the perfect audio to text service for your needs.
Your Step-By-Step Guide to Converting Audio
Ready to turn that audio file into a clean, usable transcript? Getting started with an audio to text service is actually pretty simple. It really just boils down to three main phases: uploading your file, telling the AI what to do, and exporting the final text.
Let's walk through it.
The first step is always the easiest: getting your file into the system. Modern audio to text platforms like MeowTXT have a simple drag-and-drop interface. You can toss in common audio formats like MP3 and WAV, or even video files like MP4 and MOV, straight from your computer.
Configuring Your Transcription
Once your file is uploaded, you’ll need to give the AI a few quick instructions. This is where you set the ground rules to get the most accurate audio to text result possible.
- Select the Language: Tell the AI what language is being spoken. This single step massively boosts accuracy by narrowing its focus.
- Enable Speaker Identification: If you have more than one person talking, you'll want to flip this switch. This feature (often called "diarization") labels the text with "Speaker 1," "Speaker 2," and so on. It's a lifesaver for interviews, meetings, and podcasts.
After picking your settings, you just hit the "transcribe" button and let the magic happen. The AI gets to work, converting your audio to text in a matter of minutes—often faster than the recording's actual runtime.
Here's what a typical upload screen looks like. Clean and simple.
As you can see, it's designed to get you from file to transcript with just a couple of clicks.
Editing and Exporting Your Text
Let's be real: no automated audio to text transcript is 100% perfect. That's why any good service includes an interactive editor. This tool lets you play the audio while seeing the corresponding text highlighted in real-time, making it incredibly fast to fix any wonky punctuation or misspelled names.
For a deeper dive into handling specific formats, check out our guide on how to convert MP3 to text with high accuracy.
The final step is getting your work out in a format that actually fits your project. A flexible audio to text tool should give you plenty of options so the transcript drops right into your workflow without any fuss.
When you're happy with the text, just pick an export format. The most common choices are:
- .TXT: A plain text file. Perfect for quick copy-pasting.
- .DOCX: A formatted document ready for Microsoft Word, great for reports or articles.
- .SRT: The standard subtitle file, ready to be uploaded straight to YouTube, Vimeo, or your video editor.
Still Have Questions About Audio to Text?
Diving into the world of audio to text can spark a few questions. That's totally normal. Let's clear up some of the most common ones people ask when they're just getting started with audio to text conversion.
Getting a handle on accuracy, features, and file types will help you get the most out of any transcription tool.
Just How Accurate Is Modern Audio-to-Text Software?
Under ideal conditions, today's audio to text software can hit 95% accuracy or even higher. What's "ideal"? Think crystal-clear audio, one person speaking, and a good microphone.
Of course, real-world situations are messier. Things like background noise, multiple people talking over each other, and thick accents can nudge that number down a bit. But for most everyday audio to text tasks, the accuracy is more than good enough to save you a ton of time with just a few quick edits.
Can It Figure Out Who's Talking?
Yep, most of the better audio to text tools have a feature called speaker diarization. It's a fancy way of saying the software can automatically tell when a new person starts speaking and will label their dialogue accordingly, like "Speaker 1" and "Speaker 2."
This is a game-changer for transcribing meetings, interviews, or podcasts. It makes the final audio to text transcript way easier to read because you know exactly who said what.
Without it, you'd just have a wall of text. With it, you get a coherent, readable conversation.
What Kind of Files Can I Use?
Flexibility is key, and most audio to text services support a huge range of audio and video formats. The usual suspects include:
- Audio: MP3, WAV, M4A, and FLAC are the big ones.
- Video: MP4, MOV, and AVI are almost always supported.
And when you're done, you aren't stuck with one output format. You can typically export your transcript as a plain .TXT file, a .DOCX for Word, or an .SRT file ready-made for video captions. This makes it super easy to slot the transcript right into your workflow.
Ready to see it in action? MeowTXT makes your first audio to text conversion dead simple. Get your first 15 minutes of transcription free and see how fast you can turn your audio into accurate, editable text.


