
¿Alguna vez se preguntó cómo su podcast, la grabación de una reunión o la nota de voz se convierte mágicamente en una pared de texto? La magia es una tecnología llamada Reconocimiento Automático del Habla, o ASR. Este poderoso proceso de audio a texto se ha convertido en una herramienta esencial para creadores, empresas e investigadores.
Puede pensar en ASR como un cerebro digital que ha aprendido a escuchar y escribir, al igual que una persona, pero a la velocidad de la luz. Es el motor central que impulsa cada servicio moderno de audio a texto.
¿Cómo funciona realmente el audio a texto?
Todo el proceso se siente instantáneo, pero debajo del capó, está ocurriendo una secuencia lógica de análisis. Todo comienza con el sonido en sí. Un convertidor de audio a texto no escucha palabras; procesa datos.
De las ondas sonoras a las sílabas
Cuando hablas, en realidad solo estás creando vibraciones en el aire: ondas sonoras. El primer trabajo de un sistema ASR es capturar esas ondas y convertirlas en una señal digital. Esta parte se llama modelado acústico.
Luego, el sistema divide esa compleja señal de audio en las unidades de sonido más pequeñas y básicas, llamadas fonemas. Estos son los bloques de construcción del habla, como el sonido "k" en "gato" o el sonido "sh" en "zapato".
Es muy parecido a cómo aprendemos a leer por primera vez deletreando letras individuales. La IA examina estos fonemas, los compara con una gran biblioteca de sonidos conocidos y averigua las coincidencias más probables. Este paso inicial es fundamental para una conversión precisa de audio a texto.
En esencia, la tecnología de audio a texto no solo está escuchando; está prediciendo. Calcula constantemente la probabilidad de qué palabra es más probable que siga a otra, creando oraciones coherentes a partir de una corriente de sonidos individuales.
Ensamblando palabras en oraciones
Una vez que el sistema tiene una cadena de sonidos potenciales, inicia la siguiente fase: modelado del lenguaje. Aquí es donde el contexto es rey en el proceso de audio a texto.
El ASR utiliza algoritmos sofisticados para observar la secuencia de fonemas y decidir la combinación de palabras más lógica. Sabe, por ejemplo, que la frase "helado" es mucho más probable que aparezca en una conversación que "ojos crema".
Esta infografía te ofrece una representación visual sencilla de todo el proceso, desde la entrada de sonido hasta la salida de texto.
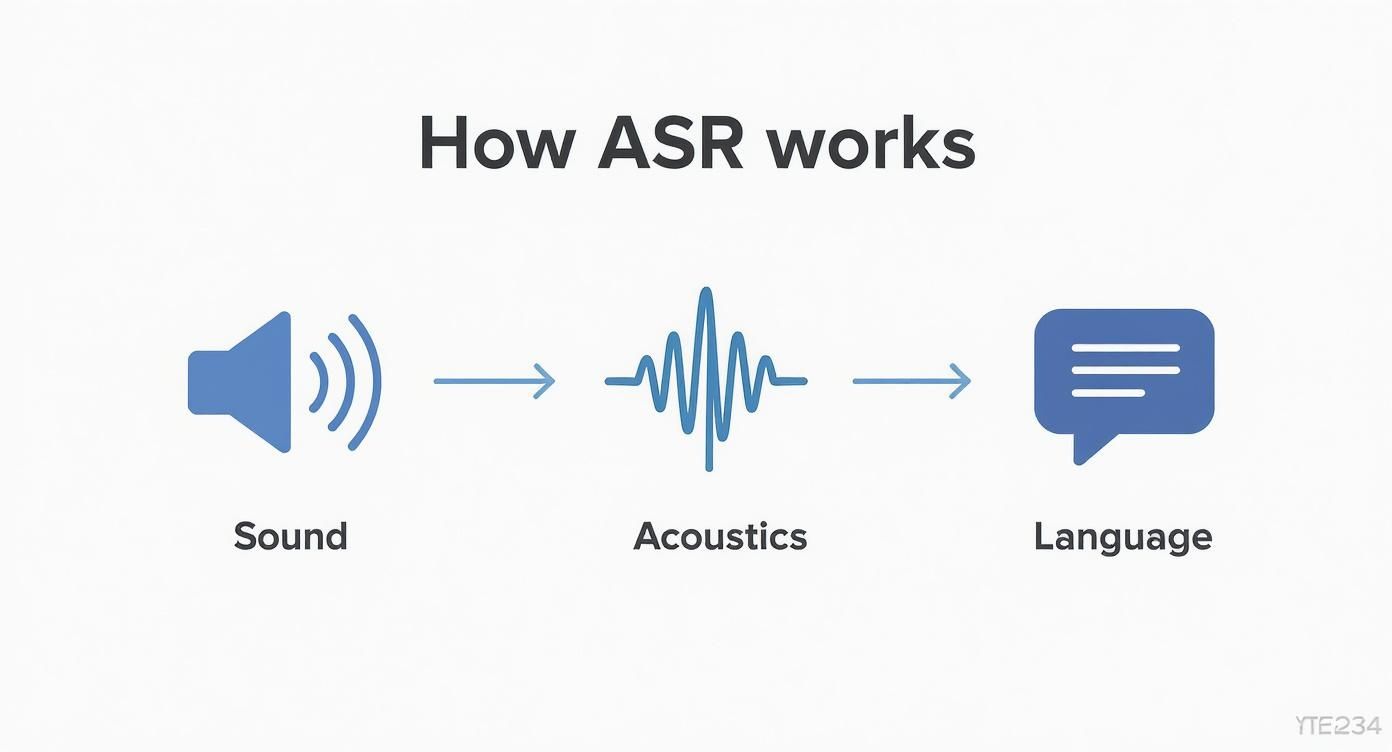
Como puede ver, el sonido bruto se analiza primero por sus propiedades acústicas. Luego, se interpreta utilizando el lenguaje y el contexto para producir el texto final. Este proceso de dos pasos es lo que permite que una IA aborde el hermoso desorden del habla humana y ofrezca una transcripción de audio a texto de alta calidad.
Para comprender realmente la mecánica, ayuda investigar la integración de IA en la postproducción moderna, que está superando los límites de lo que esta tecnología puede hacer. Al comprender tanto los modelos acústicos como los de lenguaje, comienzas a ver cómo las herramientas de transcripción actuales pueden ofrecer resultados tan asombrosamente buenos.
El viaje de la tecnología de reconocimiento de voz
La magia de convertir palabras habladas en texto en una pantalla se siente increíblemente moderna, pero sus raíces se hunden mucho más de lo que podrías pensar. Este viaje comenzó en laboratorios llenos de computadoras voluminosas del tamaño de una habitación, un mundo alejado de las elegantes aplicaciones de audio a texto que tenemos en nuestros bolsillos hoy en día. Comprender cómo llegamos aquí es la clave para apreciar cuán poderosa y accesible se ha vuelto la transcripción.
El primer intento real de reconocimiento de voz se remonta a la década de 1950 con el sistema "Audrey" de Bell Laboratories. Lanzada en 1952, esta bestia de máquina podía reconocer dígitos hablados del cero al nueve. Pero había una trampa: tenías que hacer una pausa entre cada número, y su precisión disminuía si no reconocía tu voz. Genial, pero poco práctico. Puedes profundizar en la historia de voz a texto aquí.
El cambio a modelos probabilísticos
Durante mucho tiempo, el progreso avanzó lentamente. Los primeros sistemas eran rígidos y trataban de hacer coincidir las formas de onda de audio con una plantilla predefinida. Este enfoque basado en reglas era frágil y se deshacía al enfrentarse al caos natural del habla humana: diferentes acentos, tonos y entonaciones lo desviaban por completo.
El verdadero avance se produjo cuando los investigadores comenzaron a utilizar métodos estadísticos, especialmente los Modelos Ocultos de Markov (HMM), que despegaron en la década de 1980. En lugar de buscar una coincidencia exacta, los HMM jugaban con las probabilidades.
Piénsalo como un pronóstico meteorológico para las palabras. Un HMM no solo identifica un solo sonido; calcula la probabilidad de que una secuencia de sonidos forme una palabra específica y, luego, la probabilidad de que esa palabra aparezca en una oración.
Este pensamiento probabilístico fue un cambio de juego completo. Permitió a los sistemas hacer conjeturas educadas basadas en el contexto, lo que mejoró enormemente su precisión y flexibilidad. De repente, los usos comerciales del mundo real para la tecnología de audio a texto parecían posibles.
Aprendizaje profundo y la era moderna
El siguiente gran salto adelante se produjo con el auge del aprendizaje profundo y las redes neuronales en la década de 2010. Estos sistemas de IA, que están vagamente inspirados en la estructura del cerebro humano, podrían procesar cantidades gigantescas de datos y aprender los patrones sutiles del lenguaje por sí solos.
Las herramientas de audio a texto actuales están impulsadas por estas redes increíblemente avanzadas. Han sido entrenadas con millones de horas de audio diverso, lo que les permite manejar:
- Múltiples acentos: Reconocimiento del habla de una amplia gama de hablantes globales.
- Ruido de fondo: Aislar las voces del parloteo en un café concurrido.
- Habla rápida: Seguir el ritmo de conversaciones y entrevistas rápidas.
Este entrenamiento constante es la razón por la que los servicios modernos de audio a texto pueden alcanzar tasas de precisión del 95% o más en condiciones ideales. El salto de Audrey reconociendo dígitos individuales a una IA transcribiendo una conversación compleja y natural es simplemente increíble.
Transcripción automatizada vs. humana: ¿Cuál es la adecuada para ti?
Cuando se trata de convertir audio en texto, te encuentras en una encrucijada. ¿Optas por un servicio de IA rápido o por un profesional humano orientado a los detalles? No hay una respuesta correcta: la mejor opción realmente se reduce a las necesidades específicas de tu proyecto, equilibrando cuatro factores clave: precisión, velocidad, costo y seguridad.
Piensa en un servicio impulsado por IA como el velocista. Para audio limpio y de alta calidad, como un podcast en solitario o una entrevista individual tranquila, es increíblemente rápido y puede ofrecer resultados de audio a texto sorprendentemente precisos en solo unos minutos. Este tiempo de respuesta ultrarrápido es un cambio de juego para los creadores de contenido y los especialistas en marketing que necesitan obtener transcripciones, subtítulos o notas del programa lo antes posible.
Pero donde la IA a menudo tropieza, un transcriptor humano realmente brilla.
La compensación entre velocidad y matices
Seamos claros: la transcripción humana es más lenta y cuesta más. Un profesional podría tardar unas horas o incluso un día completo en transcribir un archivo de una hora que una IA podría terminar en menos de cinco minutos. Pero lo que estás pagando es la increíble capacidad de un humano para comprender los matices, el contexto y la complejidad.
Una persona puede desenredar fácilmente conversaciones superpuestas, reconocer la jerga de la industria específica y dar sentido a los hablantes con acentos fuertes o patrones de habla extravagantes. Este toque humano se vuelve esencial para proyectos donde cada palabra importa, como declaraciones legales, registros médicos o investigaciones académicas detalladas. Si bien muchas tareas comunes, como la transcripción de entrevistas, ahora son manejadas por sofisticadas herramientas de edición de video de IA para la transcripción, la necesidad de precisión humana en escenarios de alto riesgo permanece.
La diferencia fundamental es simple: la IA transcribe lo que oye basándose en patrones, mientras que un humano transcribe lo que se pretendía basándose en la comprensión. Esto es crucial cuando se trata de sarcasmo, humor o lenguaje ambiguo que los algoritmos de audio a texto pueden malinterpretar fácilmente.
Una comparación cara a cara
Para facilitar un poco la decisión, pongamos las dos opciones una al lado de la otra. Ver sus fortalezas y debilidades expuestas puede ayudarte a elegir el enfoque perfecto para tu próximo proyecto de audio a texto.
Aquí hay una mirada directa a cómo los servicios de transcripción automatizados y humanos se comparan en los factores que más importan.
Comparación Directa entre Transcripción Automatizada y Humana
| Característica | Transcripción Automatizada (IA) | Transcripción Humana |
|---|---|---|
| Precisión | Hasta 95%+ en audio claro; problemas con ruido y acentos. | Consistentemente 99%+; excelente con audio complejo. |
| Tiempo de Entrega | Minutos para un archivo de una hora; casi instantáneo. | Varias horas a días, dependiendo de la duración del audio. |
| Costo | Muy bajo, a menudo solo unos pocos centavos por minuto. | Significativamente más alto, típicamente $1.00 o más por minuto. |
| Seguridad | Varía según el proveedor; busque cifrado y políticas de privacidad de datos. | Depende de acuerdos de confidencialidad individuales o de la empresa. |
En última instancia, la elección depende de tus prioridades. Si necesitas que se haga rápido y barato para una grabación de buena calidad, una IA de audio a texto es tu mejor opción. Pero si la precisión absoluta no es negociable, nada supera la comprensión matizada de un experto humano.
Factores que Influyen en la Precisión de la Transcripción
No todo el audio es creado igual. Ni mucho menos. La calidad de tu archivo fuente es el factor más importante que determinará si tu transcripción de audio a texto funciona o no.
Piensa en un modelo ASR como un estudiante diligente tratando de tomar notas en un aula ruidosa. Cuanto más claro sea el orador, mejores serán las notas. Si tu grabación es prístina, puedes esperar tasas de precisión que superen el 95%. Pero empieza a introducir problemas comunes, y ese número puede caer en picado bastante rápido.
El objetivo es simple: darle al motor de audio a texto la señal más limpia posible con la que trabajar. Entender qué es lo que estropea las cosas te ayuda a obtener tus grabaciones correctamente desde el principio, ahorrándote horas de limpieza dolorosa más adelante.
Calidad y Claridad del Audio
La base de cualquier gran transcripción es audio de alta calidad. No se trata de tener un estudio profesional, sino que significa usar un micrófono decente y colocarlo cerca del orador. El audio capturado desde el micrófono incorporado de un portátil al otro lado de la habitación siempre sonará delgado y distante, lo que lo convierte en una pesadilla para que los sistemas de audio a texto lo descifren.
A un nivel más técnico, cosas como el formato de grabación y la velocidad de bits también juegan un papel. Un archivo MP3 muy comprimido y de baja calidad, literalmente, tira datos de audio para ahorrar espacio. Esa información perdida puede hacer que sea mucho más difícil para una IA diferenciar entre palabras que suenan similares.
Para una inmersión más profunda en la obtención del mejor sonido posible, consulta nuestra guía sobre cómo mejorar la calidad del audio para la transcripción.
La regla general es simple: si es difícil de entender para un humano, será diez veces más difícil para una IA. El audio claro y nítido es la mejor inversión que puedes hacer para una transcripción precisa de audio a texto.
Ruido de Fondo y Variables del Orador
Incluso con un gran micrófono, el entorno de grabación puede sabotear tus esfuerzos. Un sistema ASR no puede separar fácilmente la voz de un orador del parloteo de fondo, un acondicionador de aire zumbante o el tráfico que pasa. Cada sonido extra añade otra capa de confusión que enturbia la señal para el convertidor de audio a texto.
Más allá del ruido, la forma en que la gente habla es una influencia masiva. Los principales culpables aquí son:
- Múltiples Oradores: Cuando la gente se interrumpe, el diálogo se convierte en un lío enredado que la IA tiene dificultades para desenredar.
- Acentos Fuertes: Los sistemas modernos están entrenados en una gran diversidad de acentos, pero los dialectos muy fuertes o poco comunes aún pueden confundirlos.
- Ritmo y Dicción: Hablar increíblemente rápido o murmurar tus palabras hace que sea difícil para la IA determinar dónde termina una palabra y comienza la siguiente.
Al controlar estos factores —grabando en un espacio tranquilo, animando a los oradores a hablar de uno en uno y hablando con claridad—, estás preparando tu herramienta de audio a texto para una victoria.
Cómo Elegir el Servicio de Audio a Texto Correcto

El mercado está inundado de herramientas de audio a texto, y elegir la correcta puede sentirse un poco como girar una ruleta. La verdad es que el servicio "mejor" es simplemente el que encaja perfectamente en tu mundo. Para encontrarlo, solo necesitas sopesar tus opciones frente a algunos factores clave. Este marco rápido te ayudará a encontrar una plataforma de audio a texto que coincida con tu flujo de trabajo, presupuesto y objetivos del proyecto.
Primero, verifica la compatibilidad de idioma y dialecto. ¿El servicio realmente maneja los idiomas con los que trabajas? Algunas plataformas son multiusos, mientras que otras se especializan. Si tus grabaciones están llenas de acentos regionales o dialectos específicos, querrás encontrar un servicio de audio a texto conocido por su precisión con diversos hablantes.
A continuación, piensa en cómo se integrará con tu configuración actual. Observa las opciones de integración disponibles. ¿Puedes enviar una transcripción directamente a Google Docs, o descargar un archivo SRT para tu editor de video con un solo clic? Un flujo de trabajo fluido no es solo algo bueno de tener; es un gran ahorro de tiempo.
Seguridad y Modelos de Precios
Cuando tratas con conversaciones sensibles, la seguridad no es negociable. Busca servicios de audio a texto que ofrezcan cifrado de extremo a extremo y tengan una política de privacidad de datos clara. Una plataforma que valga la pena será transparente sobre cómo protege tus archivos, asegurando que las reuniones confidenciales con clientes o las entrevistas privadas se mantengan de esa manera.
Elegir un servicio no se trata solo de características; se trata de confianza. Tus archivos de audio contienen información importante, y la plataforma de audio a texto correcta priorizará su protección con sólidas medidas de seguridad desde la carga hasta la eliminación.
Los modelos de precios están por todas partes. Algunos servicios intentarán encerrarte en una suscripción mensual o anual, lo que puede ser perjudicial si tus necesidades de transcripción son esporádicas. Otros ofrecen un modelo de pago por uso más flexible, lo que te permite pagar solo por los minutos que realmente conviertes. Esto es perfecto para proyectos únicos o si solo estás probando a usar un convertidor de audio a texto.
La tecnología ha avanzado increíblemente. Las décadas de 2000 y 2010 vieron un crecimiento explosivo, gracias a la computación en la nube y la IA. La Búsqueda por Voz de Google, por ejemplo, recopiló enormes cantidades de datos de voz, construyendo eventualmente una base de datos de 230 mil millones de palabras y alcanzando casi el 80% de precisión en 2001. Ese trabajo inicial sentó las bases para las potentes herramientas de audio a texto que tenemos hoy.
Al sopesar cuidadosamente la compatibilidad de idiomas, las integraciones, la seguridad y los precios, puedes elegir con confianza el servicio de audio a texto perfecto para tus necesidades.
Tu Guía Paso a Paso para Convertir Audio
¿Listo para convertir ese archivo de audio en una transcripción limpia y utilizable? Comenzar con un servicio de audio a texto es en realidad bastante simple. Realmente se reduce a tres fases principales: subir tu archivo, decirle a la IA qué hacer y exportar el texto final.
Vamos a repasarla.
El primer paso siempre es el más fácil: ingresar tu archivo en el sistema. Las plataformas modernas de audio a texto como MeowTXT tienen una interfaz simple de arrastrar y soltar. Puedes agregar formatos de audio comunes como MP3 y WAV, o incluso archivos de video como MP4 y MOV, directamente desde tu computadora.
Configurando Tu Transcripción
Una vez que tu archivo se ha subido, deberás darle a la IA algunas instrucciones rápidas. Aquí es donde estableces las reglas básicas para obtener el resultado de audio a texto más preciso posible.
- Selecciona el idioma: Dile a la IA qué idioma se está hablando. Este único paso aumenta masivamente la precisión al reducir su enfoque.
- Habilita la identificación del hablante: Si hay más de una persona hablando, querrás activar este interruptor. Esta función (a menudo llamada "diarización") etiqueta el texto con "Hablante 1," "Hablante 2," y así sucesivamente. Es un salvavidas para entrevistas, reuniones y podcasts.
Después de elegir tu configuración, simplemente presiona el botón "transcribir" y deja que la magia suceda. La IA se pone a trabajar, convirtiendo tu audio a texto en cuestión de minutos, a menudo más rápido que la duración real de la grabación.
Así es como se ve una pantalla de carga típica. Limpio y sencillo.
Como puede ver, está diseñado para llevarlo del archivo a la transcripción con solo un par de clics.
Edición y exportación de su texto
Seamos realistas: ninguna transcripción de audio a texto automatizada es 100% perfecta. Por eso, cualquier buen servicio incluye un editor interactivo. Esta herramienta le permite reproducir el audio mientras ve el texto correspondiente resaltado en tiempo real, lo que hace que sea increíblemente rápido arreglar cualquier puntuación extraña o nombres mal escritos.
Para profundizar en el manejo de formatos específicos, consulte nuestra guía sobre cómo convertir MP3 a texto con alta precisión.
El paso final es obtener su trabajo en un formato que realmente se ajuste a su proyecto. Una herramienta flexible de audio a texto debe brindarle muchas opciones para que la transcripción se ajuste directamente a su flujo de trabajo sin problemas.
Cuando esté satisfecho con el texto, simplemente elija un formato de exportación. Las opciones más comunes son:
- .TXT: Un archivo de texto plano. Perfecto para copiar y pegar rápidamente.
- .DOCX: Un documento formateado listo para Microsoft Word, ideal para informes o artículos.
- .SRT: El archivo de subtítulos estándar, listo para ser subido directamente a YouTube, Vimeo o su editor de video.
¿Todavía tiene preguntas sobre audio a texto?
Profundizar en el mundo del audio a texto puede generar algunas preguntas. Eso es totalmente normal. Aclaremos algunas de las más comunes que las personas hacen cuando recién comienzan con la conversión de audio a texto.
Comprender la precisión, las características y los tipos de archivos lo ayudará a aprovechar al máximo cualquier herramienta de transcripción.
¿Qué tan preciso es el software moderno de audio a texto?
En condiciones ideales, el software actual de audio a texto puede alcanzar una precisión del 95% o incluso superior. ¿Qué es "ideal"? Piense en audio nítido, una persona hablando y un buen micrófono.
Por supuesto, las situaciones del mundo real son más desordenadas. Cosas como el ruido de fondo, varias personas hablando entre sí y acentos fuertes pueden reducir un poco ese número. Pero para la mayoría de las tareas diarias de audio a texto, la precisión es más que suficiente para ahorrarle mucho tiempo con solo algunas ediciones rápidas.
¿Puede averiguar quién está hablando?
Sí, la mayoría de las mejores herramientas de audio a texto tienen una función llamada diarización del hablante. Es una forma elegante de decir que el software puede decir automáticamente cuándo una nueva persona comienza a hablar y etiquetará su diálogo en consecuencia, como "Orador 1" y "Orador 2".
Esto cambia las reglas del juego para transcribir reuniones, entrevistas o podcasts. Hace que la transcripción final de audio a texto sea mucho más fácil de leer porque sabe exactamente quién dijo qué.
Sin ella, solo tendría una pared de texto. Con ella, obtienes una conversación coherente y legible.
¿Qué tipo de archivos puedo usar?
La flexibilidad es clave, y la mayoría de los servicios de audio a texto admiten una gran variedad de formatos de audio y video. Los sospechosos habituales incluyen:
- Audio: MP3, WAV, M4A y FLAC son los más importantes.
- Video: MP4, MOV y AVI casi siempre son compatibles.
Y cuando haya terminado, no estará atascado con un formato de salida. Por lo general, puede exportar su transcripción como un archivo .TXT plano, un archivo .DOCX para Word o un archivo .SRT ya preparado para subtítulos de video. Esto hace que sea muy fácil integrar la transcripción directamente en su flujo de trabajo.
¿Listo para verlo en acción? MeowTXT hace que su primera conversión de audio a texto sea muy sencilla. Obtenga sus primeros 15 minutos de transcripción gratis y vea qué tan rápido puede convertir su audio en texto preciso y editable.


