Ever watched a TikTok video with real-time captions? Or asked your smart speaker for the weather? If you nodded yes, you’ve already used Automatic Speech Recognition (ASR). This AI technology processes human speech into readable, searchable text, and it's the invisible engine behind applications we use every day.
A Digital Scribe for the Modern Age
Think of ASR as an incredibly fast digital transcriber. It's the AI that powers tools we rely on daily, from the voice-to-text feature on your phone to the live captions in your last video call. To fully grasp what ASR is, you have to see it as a core component of the broader field of Artificial Intelligence (AI). ASR systems use sophisticated algorithms to analyze audio waveforms, identify patterns in human speech, and convert those patterns into text.
This capability makes audio and video data more accessible and valuable than ever before. For instance, without ASR, your voice commands to devices like Siri or Alexa just wouldn't work. It’s the foundational first step that turns spoken words into data that computers can actually understand and act on.
The Growing Importance of ASR
And the demand for this tech is exploding. As a key piece of conversational AI, the global ASR software market is on a massive growth trajectory, projected to leap from USD 5.49 billion to an incredible USD 59.39 billion by 2035. That's a compound annual growth rate (CAGR) of 26.67%, which shows just how deeply it’s becoming integrated into our lives. You can dig into the full market analysis to understand more about this explosive growth.
ASR is no longer a futuristic concept; it is a fundamental utility that unlocks the value hidden within spoken content, making it searchable, analyzable, and accessible to everyone.
A few key factors are driving this rapid adoption:
- Improved Accessibility: It delivers captions for the hearing impaired and makes audio content searchable for everyone.
- Data Insights: Businesses can transcribe customer calls or meetings to analyze feedback and spot trends.
- Enhanced Efficiency: Professionals can quickly convert interviews, lectures, and notes into text, saving hours of painstaking manual work.
As this technology keeps getting better, its presence in our digital lives will only become more seamless and essential.
How ASR Technology Translates Speech into Text
At its core, Automatic Speech Recognition (ASR) is a bit like teaching a computer to do what a human transcriber does naturally: listen to someone speak and write it all down. The tech takes a raw audio file—which is really just a continuous sound wave—and methodically turns it into clean, readable text. It's a fascinating process that blends acoustics, linguistics, and some seriously powerful AI.
This visual breaks down that high-level journey from sound to text.
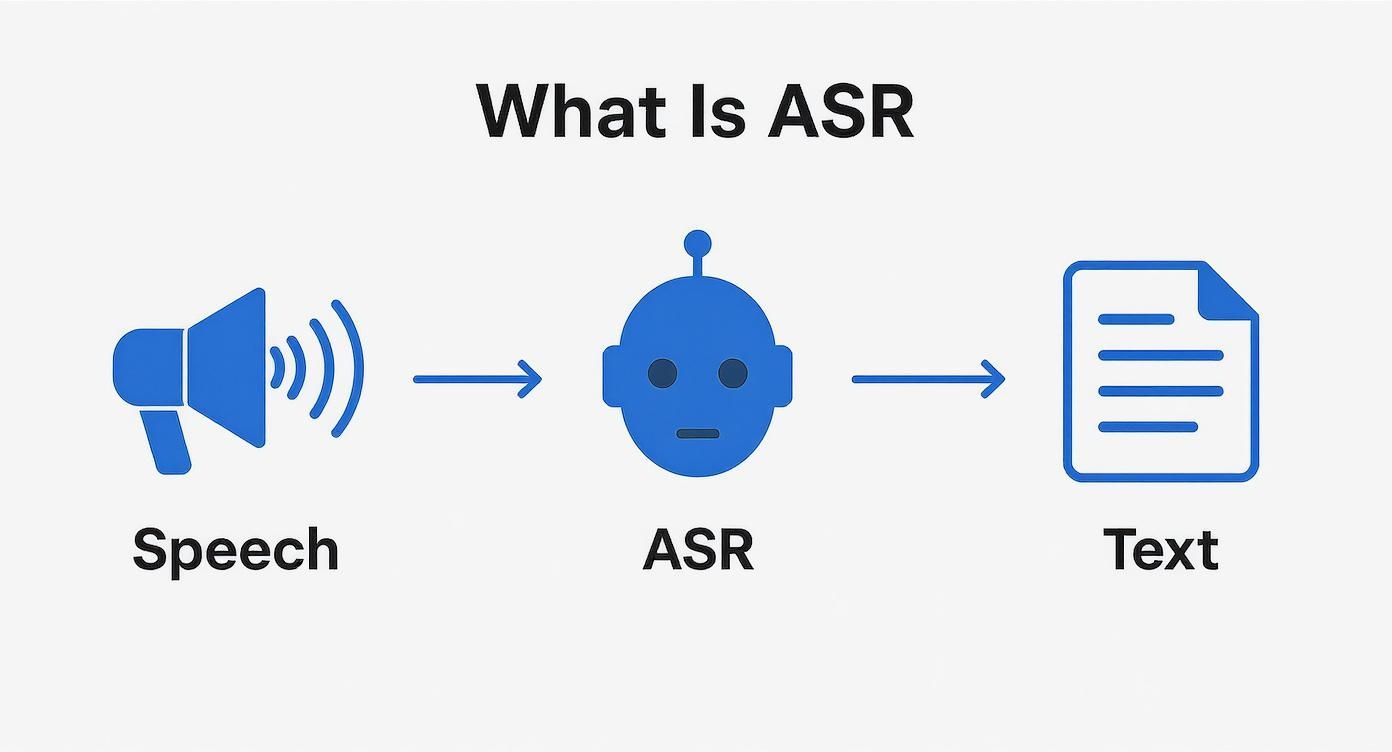
As the infographic shows, the ASR system is the essential bridge between a spoken sound wave and a final text document. Getting this fundamental conversion right is the first and most critical step in unlocking the value hidden in any audio data.
Today, there are two main approaches to Automatic Speech Recognition. Understanding both helps explain why ASR has gotten so incredibly good in recent years.
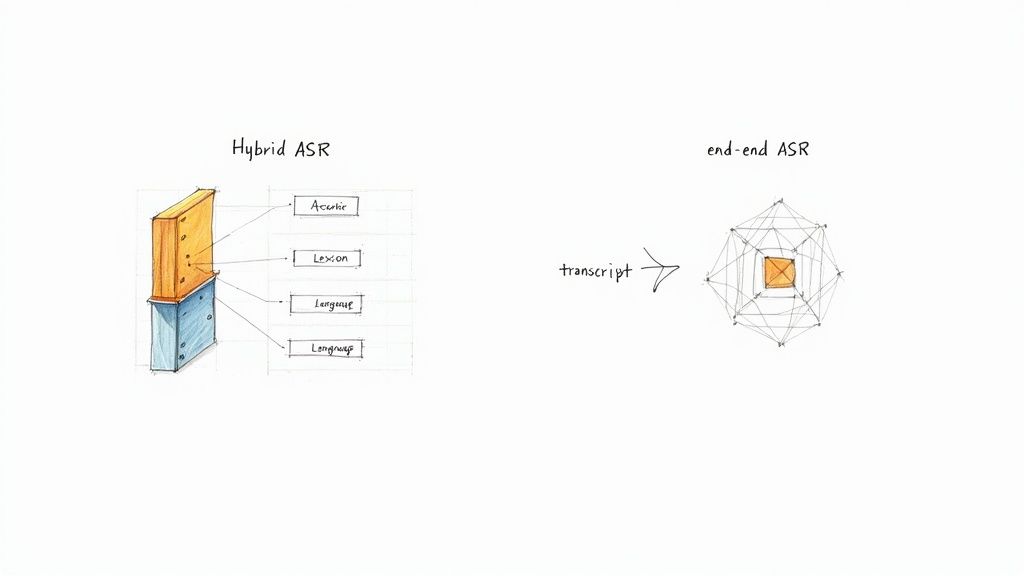
The Traditional Hybrid Approach
The first method is the traditional hybrid model. Think of it like a highly specialized assembly line with a team of experts. Each expert has one specific job, and the final transcript is only as good as the weakest link in the chain.
This approach combines three separate models:
- The Acoustic Model: This specialist is the listener. Its job is to take in audio waveforms and predict the smallest units of sound, called phonemes. It's basically answering the question, "What individual sounds am I hearing right now?"
- The Lexicon Model: This is the team's dictionary. It takes the stream of phonemes from the Acoustic Model and maps them to actual words. It's the part that knows the sounds "h-eh-l-oh" match up with the word "hello."
- The Language Model: This is the grammar guru. It looks at a sequence of words and predicts what's most likely to come next based on statistical patterns. This is how the system distinguishes between sensible phrases like "write a letter" and nonsensical ones like "right a letter."
These three components had to work in perfect sequence to piece together the final text. While this method worked for years, it had a major bottleneck: each part had to be trained separately, making it time and labor-intensive, and accuracy eventually plateaued.
The Modern End-to-End AI Approach
The second, and much more recent, method is the end-to-end AI model. Instead of that assembly line, imagine a single, brilliant expert who learned their craft by listening to millions of hours of real-world audio. This expert figures out how to map sound directly to text in one fluid step.
This is the engine powering the most advanced ASR systems today.
An end-to-end AI model doesn't need separate acoustic, lexicon, and language models. It employs a single unified model that directly maps a sequence of input acoustic features into a sequence of words. It learns all the complex, messy relationships between sounds, words, and grammar simultaneously by analyzing massive datasets.
This unified approach isn't just more efficient; it's also far more accurate. By learning from such a vast and varied diet of audio, these AI models get much better at handling real-world chaos like accents, background noise, and slang.
This modern method is the real reason we're seeing such dramatic leaps in transcription quality. If you want to see this tech in action, our guide on converting audio to text offers a practical look at how these systems perform. The uncanny ability of these end-to-end models to constantly learn and adapt is what's pushing ASR ever closer to human-level accuracy.
Exploring Traditional vs. Modern ASR Systems
If you peek under the hood of Automatic Speech Recognition, you'll find two completely different engines at work. For years, the field was dominated by a traditional, multi-part approach. But more recently, a unified, AI-driven method has taken over, delivering breakthroughs in accuracy and accessibility.
Understanding this shift is the key to seeing why ASR has improved so dramatically in such a short time.
The old-school "hybrid" systems were clever, but they were also incredibly complicated. They hit a wall in accuracy because they were made of so many separate, hand-tuned pieces. Each part required its own team of specialists and a ton of manual work, like expert phoneticians, to get right.
Think about it: you used to need expert phoneticians just to build the phonetic dictionary for your system. This made traditional models not only complex and expensive to create but also agonizingly slow to improve.
Modern end-to-end AI models flipped the script entirely. These systems learn directly from massive amounts of audio, completely bypassing the need for separate, hand-built components.
The AI Advantage in Speech Recognition
So, why the big shift to AI? It really comes down to a few core advantages, starting with accuracy.
End-to-end models are trained on millions of hours of real-world audio. This means they're far better at handling the beautiful messiness of human speech—from thick accents and regional dialects to background noise and people talking over each other.
This approach also radically simplifies the whole training process. Instead of juggling three separate models, developers can focus on a single, unified system. This makes it far easier to update and improve performance. As conversational AI gets smarter, so do the tools built on it. You can see this evolution in action when you look at whether ChatGPT can transcribe audio and its place in this new landscape.
A Head-to-Head Comparison
To make the differences crystal clear, it helps to see these two approaches side-by-side. The contrast in their architecture, data needs, and potential for improvement shows exactly why the industry has moved so decisively toward AI.
Key Differences Between ASR Approaches
| Aspect | Traditional Hybrid Approach | End-to-End AI Approach |
|---|---|---|
| Components | Lexicon + Acoustic + Language Models | Single unified model |
| Training Data | Requires force-aligned data | Works with unaligned audio-text pairs |
| Human Labor | High (phoneticians, manual alignment) | Minimal |
| Accuracy Trend | Plateaued | Continuously improving |
| Setup Complexity | High (multiple independent models) | Lower (single integrated system) |
| Customization | Requires expert knowledge and effort | Can be fine-tuned with new data |
As you can see, the practical advantages of modern AI models are huge. Their simpler architecture and data-driven learning process don't just produce better results—they also open the door for much faster innovation in speech recognition.
Measuring ASR Accuracy with Word Error Rate
So, how do we know if one speech recognition system is actually better than another? The industry standard for measuring ASR accuracy is a metric called Word Error Rate (WER).
Think of it as a simple, straightforward way to grade a machine-generated transcript against a perfect, human-verified reference transcript.
WER calculates the percentage of errors by counting every single mistake the ASR makes. The formula is: WER = (Substitutions + Deletions + Insertions) / Number of Words in Reference Transcript. That total is then divided by the number of words in the correct transcript.
The goal? Get the lowest WER possible. A lower score means a more accurate transcript.
A WER of 10% means the transcript is 90% accurate. A top-tier system might hit a WER of 3%, getting 97% of the words right. That small percentage point difference can be the deciding factor between a useful tool and a frustrating mess.
Why WER Isn't the Full Story
While WER is the industry standard for measuring ASR accuracy, it doesn't capture the whole picture of how a system performs in the real world. A low score is great, but life rarely happens in a quiet, sound-proof studio.
Real-world audio presents multiple challenges that can throw off even the most advanced models.
Here are some of the most common challenges:
- Background Noise: The clatter of a coffee shop, street traffic, or poor audio quality can easily confuse the system.
- Overlapping Speakers: When people talk over each other, the ASR struggles to separate the dialogue and assign it to the right person.
- Accents and Dialects: Models trained on "standard" American or British English can get tripped up by unique accents or speaking styles.
- Industry-Specific Jargon: Technical terms, brand names, or slang that aren't in the model’s vocabulary often get transcribed into something completely bizarre.
These real-world issues are exactly why a good audio to text converter needs to be robust. A system might have an impressive WER on clean lab data, but its true value is proven by how well it handles the messy, unpredictable nature of everyday audio. This is where modern AI models, trained on millions of hours of diverse sound, truly start to pull away from older technologies.
Real-World Applications of ASR Technology
Automatic Speech Recognition has long since broken out of the lab and moved way beyond simple voice commands. Today, modern ASR delivers measurable value across diverse industries like telephony, video platforms, and media monitoring.
You can see this shift everywhere. ASR is now the main engine driving the entire speech recognition field, with explosive growth in customer service, healthcare, and media. Features that once felt like science fiction, like real-time transcription, are now just part of the workflow.
Transforming Customer Engagement and Media
Nowhere is the impact of ASR clearer than in the modern contact center. In the past, managers would manually review a tiny, random sample of customer calls for quality control. It was a shot in the dark. Now, they can transcribe 100% of their interactions.
This simple change turns a flood of unstructured audio into a searchable, analyzable database. Businesses can instantly scan calls for customer sentiment, spot recurring problems, and confirm agents are sticking to compliance scripts. It’s a complete flip from being reactive to being proactive and data-driven.
The media and entertainment world has been just as transformed.
- Video Platforms: Think of services like YouTube. They use ASR to automatically generate captions, making their content instantly accessible to a global audience and those who are deaf or hard of hearing.
- Media Monitoring: Brands now use ASR to scan thousands of hours of podcasts and broadcast news. They can track mentions of their company, gauge public opinion, and measure the real impact of their PR campaigns.
- Content Creation: Video editors and podcasters use ASR transcripts to slash production time. Instead of scrubbing through hours of audio to find a specific quote, they can just hit
Ctrl+F.
Boosting Productivity in the Modern Workplace
Virtual meetings are the backbone of modern work, and ASR is making them far more effective. Platforms like Zoom and Google Meet use the technology to provide real-time transcription, so no one ever misses a crucial point.
But the real magic happens after the meeting ends. These transcripts become invaluable assets. You can use them to generate instant meeting minutes, pull out action items, and create a permanent, searchable record of every decision. It completely eliminates the need for frantic note-taking. When looking at what drives these features, you’ll often find reviews of the top speech-to-text software that powers them.
ASR’s true value lies in its ability to turn unstructured, fleeting spoken conversations into structured, permanent data that can be analyzed, searched, and repurposed.
From transcribing doctor-patient conversations in healthcare to helping students turn lectures into study guides, the applications just keep growing. ASR is the key that unlocks the massive value hidden inside the spoken word.
ASR FAQs
As you get more familiar with Automatic Speech Recognition, a few common questions tend to pop up. Getting these sorted helps clarify how ASR fits into the wider world of voice tech and artificial intelligence. Let's clear up any lingering confusion.
What Is the Difference Between ASR and NLP?
Think of ASR as the ears and Natural Language Processing (NLP) as the brain—they work together in Voice AI applications.
- ASR (Automatic Speech Recognition) is the ears of the operation. Its one and only job is to convert spoken audio into written text. It answers the question: what was said?
- NLP (Natural Language Processing) is the brain. It takes the text that ASR provides and analyzes it to understand meaning, intent, and sentiment.
Picture this: you ask your smart speaker, "What's the weather like in London tomorrow?" ASR does the first part, converting your speech into the text: "What's the weather like in London tomorrow?". Then, NLP kicks in, analyzing that text to figure out your core request—a weather forecast for a specific place and time—so the device can grab the right information for you.
Is ASR the Same As Speech-to-Text?
Yes. For all practical purposes, ASR and speech-to-text are used interchangeably. They both refer to the same technology.
"Automatic Speech Recognition" is the underlying technology, while "speech-to-text" describes the function it performs. If you're looking for a tool that turns audio into words, searching for either term will get you where you need to go.
What Is the Difference Between Speech Recognition and Voice Recognition?
This is a classic point of confusion, but the distinction is actually pretty simple. Speech recognition transcribes what is being said, while voice recognition identifies who is speaking.
Speech recognition is all about identifying what is being said. The goal is to transcribe spoken words into text, no matter who is speaking. A tool that generates subtitles for a YouTube video or creates meeting minutes is using speech recognition.
Voice recognition—often called speaker recognition or voice biometrics—focuses on identifying who is speaking. It analyzes unique voiceprints to match a voice. A security system that unlocks your phone when you say a specific phrase is using voice recognition to confirm it's really you.
In short: Speech recognition creates transcripts. Voice recognition labels speakers.
How Accurate Is Modern ASR Compared to Humans?
This is where things get really interesting. Under ideal conditions—think one person speaking clearly into a good microphone in a quiet room—the best modern ASR systems can achieve Word Error Rates below 5%, approaching human-level accuracy.
But the real world is messy. Performance varies with background noise, accents, and overlapping speakers, where humans still maintain advantages in contextual understanding. That said, the accuracy gap is closing at an incredible pace as sophisticated AI models learn from vast amounts of audio data every single day.
Ready to put this powerful technology to work? MeowTxt offers a simple, pay-as-you-go solution for converting your audio and video files into accurate, editable text in minutes. Try it for free and get your first 15 minutes of transcription on us.


